Thinking on what jotak said:
“A best effort would be to “act” as a MPD server and give information on 6600 presented the same way MPD does, but including information from other sources. But I would probably not go for it, since it would be a lot of work and we’ve already much to do.”
This is the way to go in my opinion. It is actually quite a big work to do. But this will allow us all the flexibility we need. And in the end we’ll be able to manage all the services in a simpler way, wrapping every request and every response in appropriate way.
Plus, we would have implemented this mechanism on evey single service anyway, so in the end the additional work is just miming mpd protocols and hooking to our methods.
Here are some additional thoughts about play queue and db, and volumio core engine:
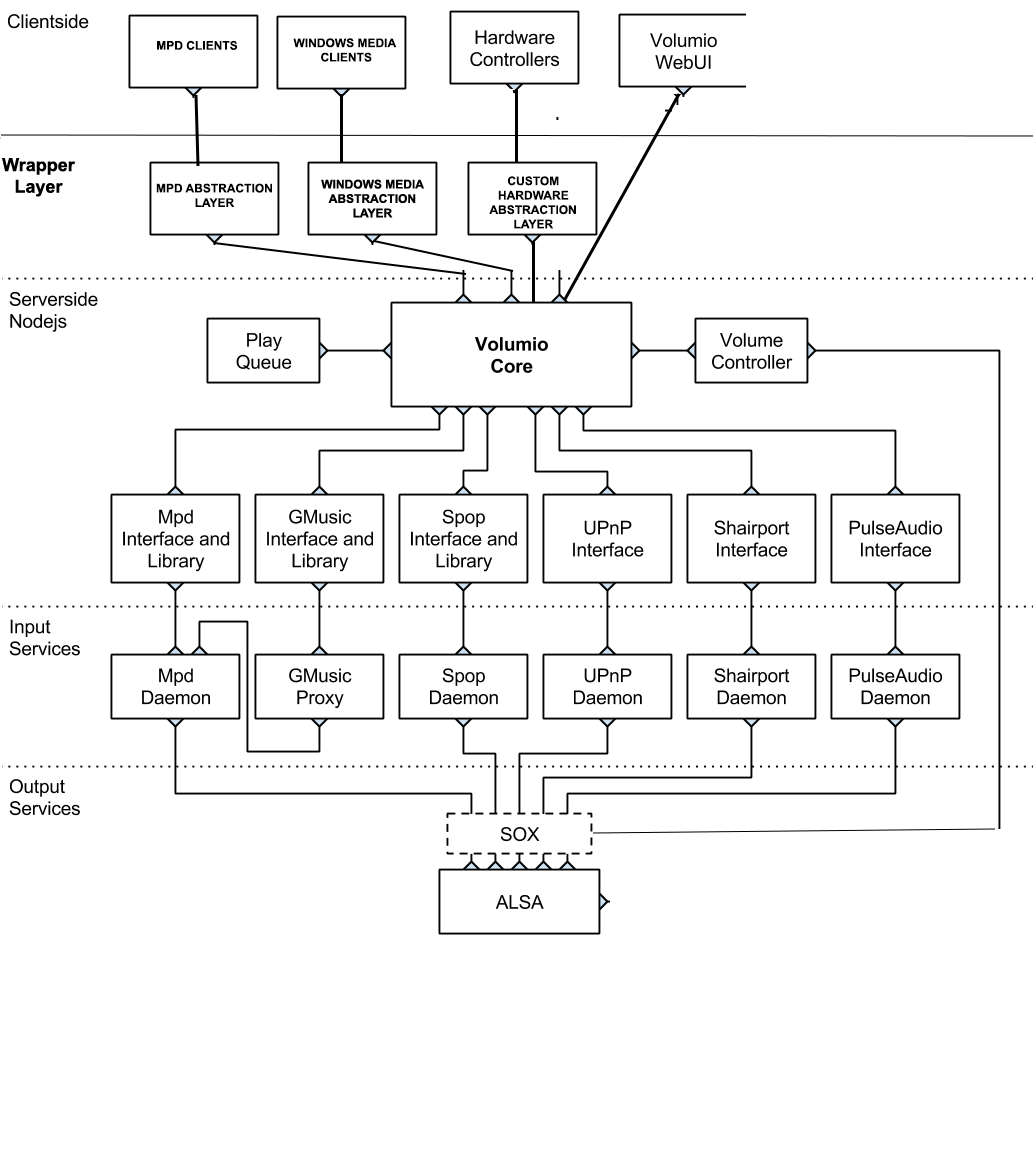
- To mantain compatibility with third party clients and ensure we have full control and flexibility over play queue my opinion is that exposing our core as mpd is the key.
This way we are basically acting as mpd, on port 6600, and receiving commands (and sending status) from there.
The idea is to use a single playlist, listing every item (mpd, spotify, gmusic etc). It will be exposed as regular mpd playlist. Once played, every item will be played by the correspondent service. This playback mechanism will be handled by volumio core, and the status will be sent to clients\web ui as it was mpd.
So we are miming what mpd does, but implementing the playback mechanism we want for every service.
So this is what goes on:
WebUI and Clients connect to Volumio core on 6600, with same MPD protocol
We have our play queue exposed as normal mpd queue, even if there are non-mpd items.
We define the parameters for each item type. Like: service, daemon, port, communication protocol etc.
When we receive a play command from client\webui, we just play the item according to the above rules.
We notify status via mpd protocol to client\webui
Scenario:
Playlist
1- mpd item
2- spop item
3- gmusic item
4- mpd item
From Client\WebUI
- I see the complete playlist. I enqueue it and play
On Volumio Core
- I receive the add & play command
- I look into my db and set each item type, and which playback mechanism I should use:
Play track one, send mpd play for mpd item, mpd plays it.
When mpd finishes playing it, I know I should use spop now.
Play second track with spop, sending appropriate spop commands
When spop track finishes
I send play with gmusic parameters and so on
Other scenario (search)
On Client\WebUI, the user searchs for “Bowie”
Volumio core receives “search bowie” on 6600 like it was mpd
For every active service, volumio core queries every service and reports results to volumio core
Volumio core then wraps results and sends them in mpd response format to client on 6600 (eventually adding tags to tell if is a mp3, spotify or google music, for example adding a [SPOTIFY] to tile)
WebUI\Client selects a spotify reply and plays it, sending addid (id of results) to 6600
Volumio core interpretes the id and sends to spop the appropriate play command
So what we need to do:
1- Recreate and mime mpd behavior on listen\send status
2- Implement the controlling pattern for every service. Ideally we should define the same type of methods and patterns for every service type.
3- Define our db structure to know which item type we have, and all additional information (rating system…)
ADDITIONAL CLIENTS support
To ensure future compatibility with other clients (spotify connect, windows media etc) a good idea would be designing the mpd control wrapper as a separate layer. This way we’ll have a Volumio Core API which could be used to hook just mpd initially, and then extended in a simple way with other protocols. There is not much additional work in the Volumio core, but it would be definetely a good idea.
As an implementation note, we shold think in a more abstract way, not tie our methods exclusively to mpd one’s.
Otherwise for each new service wrapper integration we can occur in alose lose situation
E.g. consider the mpd play call wich take just the ID parameter. Thevolumio core api should expose a play method wich takes for example a
map of key – value, in such way the wrapper will be able to parse tompd play call, put the ID parameter into the map and call the Volumio
Core play method.
The volumio core play method read the request and call the appropriateservice (spoop, mpd or another) with all the required parameters
needed by the service API, In this way the same volumio core API wiilbe able to run (through) the specific implementation any service play
call.
Conclusion and potential issues:
- The initial phase will be quite a big task, lot of work involved. But when this will be completed, the rest of development should be pretty fast.
- The system will be modular, thus quite complex. We should assess if this will compromise system performances
- This will be a great step forward. There could be good chances that Volumio will be THE audio player
- We are a great team of 5 people now. I’m sure all the right ingredients are there
What do you guys think?